Une IA qui comprend les visages
Published on Aug 4, 2020.Le projet, sa portée philosophique
Dans cet article je vais vous présenter un projet que j'apprécie beaucoup, car il a un côté technique très avancé, mais également une portée philosophique qui promet de nombreux débats ! J'ai pu discuter et débattre de ce projet avec beaucoup de personnes totalement extérieur à l'informatique, ce qui montre que l'IA est un domaine de l'informatique qui a un impact social important.
L'objectif est de créer un programme capable de créer des visages à partir d'exemples. On veut pouvoir reproduire un visage mais également en générer de nouveaux à partir de rien. Pour cela nous allons utiliser une technique de machine learning, appelée auto-encodeur. C'est un type de réseau de neurones qui a pour but de synthétiser une information.
Pour atteindre ce but, le réseau prend une information dans sa taille originale, et apprend à la compresser (synthétiser) pour ensuite recréer l'originale. On apprend à un réseau à conserver le maximum d'informations tout en réduisant sa dimension.
Si cela paraît abstrait, voici une application concrète: on donne au programme un texte de 1000 mots, il apprend à le synthétiser en seulement 100 mots, et apprend ensuite à rajouter les détails afin de reconstituer l'original de 1000 mots. Nous allons faire la même chose mais avec des images. Nous allons lui donner une image représentant un étudiant de face en 64x64 pixels, puis le réseau apprend à la synthétiser en seulement quelques informations, pour ensuite redonner une image de 64x64 pixels.
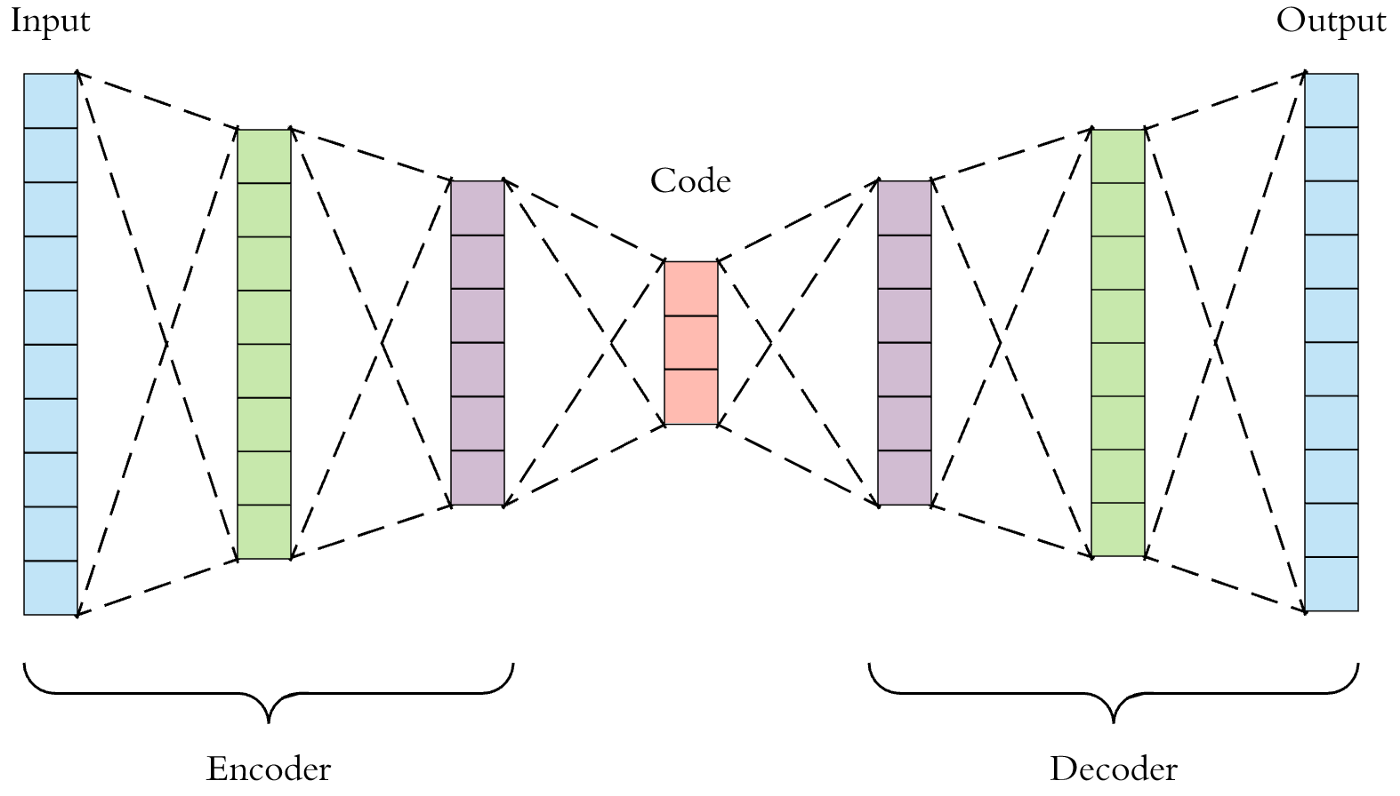
La partie "Encoder" apprend à synthétiser l'information (réduire sa dimension), le code correspond à la synthèse, au résumé de l'information, et la partie "Decoder" apprend à recréer l'information complète depuis la synthèse.
On peut voir ici une analogie avec l'apprentissage humain. À l'école primaire on apprend aux enfants à lire un texte et à en écrire un résumé: c'est l'encodeur. Une fois que l'enfant à écrit son résumé, il se fait corriger par son instituteur qui vérifie que le résumé reprend bien les informations principales du texte: c'est le décodeur. Avec cet exercice, on vise à s'assurer que les enfants comprennent le texte, en y gardant les informations clés à sa compréhension. C'est la même chose avec notre IA.
Nous avons donc une idée fonctionnelle sur le papier, il nous faut cependant une source d'apprentissage ! En effet, les enfants d'école maternelle doivent avoir un support. Vous vous doutez bien que l'instituteur ne choisit pas les textes au hasard: ils doivent être à la portée des élèves, dans le sens et la quantité. Pour notre IA c'est pareil, on doit avoir des images assez simples à synthétiser, et pas trop lourdes car nous sommes limitées en puissance et en temps. Pour faciliter au maximum l'apprentissage, il faut que les images aient le même fond, le même éclairage et le même cadrage. Comme ça l'IA peut se concentrer uniquement sur ce qui nous intéresse: le visage. J'ai donc décidé d'utiliser les images des étudiants de mon école, 42, qui correspondent bien à tous ces critères. Nous allons compresser les images en 1000 informations.
L'IA sait apprendre, sait-elle comprendre ?
Synthétiser une information, c'est faire une abstraction. Quand notre programme va réduire une image représentant un visage en seulement 1000 informations, il va faire des abstractions. Il va convertir une information factuelle, mathématique, numérique, la couleur et l'intensité du pixel d'une image, en une caractéristique On passe d'un tableau de couleurs à un tableau de traits de visages: largeur du visage, sexe, longueur des cheveux, couleur des yeux...
Notre cerveau fonctionne de la même manière inconsciemment. Si vous arrivez à lire un livre, votre cerveau n'interprète pas directement le positionnement des points d'encre sur le papier: il fait des abstractions, d'abord en lignes, puis en lettres, en mots, et ensuite il met du sens derrière ces mots.
Peut-on dire que notre programme comprend ce qu'est un visage ? Personnellement je dirais que oui, on est face à une réelle forme d'intelligence, même si très limitée dans sa globalité. Dans un futur avec des progrès immenses en puissance informatique, peut-être que ce genre de programme constituerait un bloc élémentaire d'une intelligence plus globale, qui aurait pour but d'entraîner et gérer tous ces blocs élémentaires. Le tout est de se fixer sur une définition de la compréhension et de l'intelligence, mais pour moi ce genre d'exemple dépasse largement les simples statistiques.
La technique
Je vais utiliser Keras en Python. Voici comment j'ai défini le modèle:
# Création du modèle
model = tf.keras.Sequential()
# Partie encodeur
model.add(tf.keras.layers.Dense(20000, input_shape=(12288,), activation='sigmoid'))
model.add(tf.keras.layers.Dense(15000, activation='relu'))
# L'output de ce layer est le code, l'information synthétisée
model.add(tf.keras.layers.Dense(1000, activation='relu'))
# Partie décodeur
model.add(tf.keras.layers.Dense(15000, activation='relu'))
model.add(tf.keras.layers.Dense(20000, activation='relu'))
# On veut que cette sortie soit identique à notre input, pour reconstituer l'image originale
model.add(tf.keras.layers.Dense(12288, activation='sigmoid'))
# On affiche un résumé de notre modèle
model.summary()
# On compile notre modèle
model.compile(optimizer='adam', loss='mean_squared_error')Je passe la partie chargement et traitement des images, elles sont seulement toutes coupées en 64x64, voici mon image de profile:

Comme vous pouvez constater la résolution est vraiment basse, malheureusement je suis assez limité techniquement pour le moment. Viens ensuite l'entraînement du modèle que l'on a créé, on cherche à minimiser la différence entre l'image d'entrée et de sortie:
history = model.fit(train_set, train_set, epochs=60, batch_size=32, validation_data=(test_set, test_set))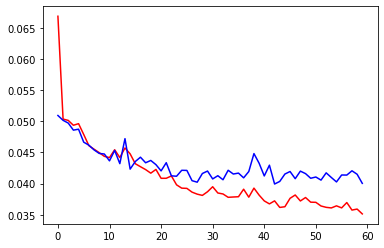
Le résultat
Voici quelques images générées grâce à la partie décodeur, qui prend une information synthétisée pour la développer:




C'est très flou et peu défini, mais on peut clairement voir que l'IA a compris des notions comme le sexe, la forme du visage, l'épaisseur des sourcils.
Aller plus loin
Pour aller plus loin, il serait très intéressant d'utiliser des couches à convolution, beaucoup plus performantes pour la reconnaissance de paternes dans un espace en 2 dimensions. On pourrait également ajouter plus de neurones dans les couches cachées, et bien sûr trouver une source de données avec beaucoup plus d'exemples.